KTC Energiportal, Operatörsmanual
Denna sida beskriver hur man administrerar KTC:s energiportal med verktyget IMC. Den finns kvar som referens, även om KTC rekommenderar att systemet så långt det går administreras via web.
Inledning
Energiportalen är ett verktyg som riktar sig till fastighetsägare med ett helt bestånd av fastigheter, och ger möjlighet till en effektiv uppföljning av t ex energi- och vattenanvändning. Det finns två huvudsakliga syften:
1) Analysera och hitta byggnader som använder onormalt mycket energi, för att kunna sätta in åtgärder.
2) Underlätta rapportering inom företaget om hur man uppfyller sin budget och sina mål för energioptimering.
I manualen används emellanåt namnet "Analyser". Det härrör från hur systemet är uppbyggt. Det finns en bas av funktioner som hanterar data på ett generellt plan, och på det modulen Analyser som fokuserar just på förbrukningar kopplade till fastigheter.
Begrepp i Energiportalen
För att förtydliga vad som menas med olika begrepp i handboken beskrivs här nedan de viktigaste begreppen i en ordlista nedan.
Navigationsträd
Navigationsträd är centralt i Energiportalen och är en beskrivning av fastighetsbeståndet i form av ett träd.
För att energiförbrukningen skall kunna följa upp som en summa av ett antal byggnader krävs att det finns en nod i navigationsträdet. Med strukturen nedan summeras mätarna från de fyra byggnaderna Remonthagen Hus 1-4 upp till fastigheten Remonthagen. Fastigheten summeras i sin tur upp i området Ryttarvägen.
Trädet behöver innehålla byggnader och fastigheter. I övrigt kan man bygga trädet för att täcka just de behov man har i den aktuella installationen.
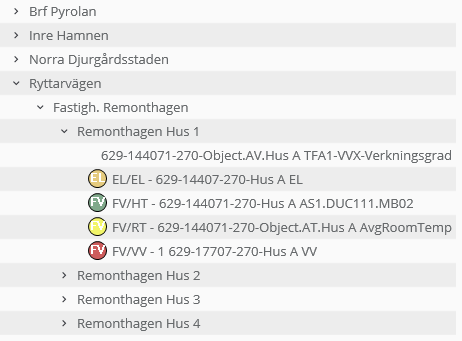
Nodtyp
Varje "nod" i trädet är en nodtyp. I Energiportalen finns ett antal fördefinierade nodtyper; Kund, Område, Fastighet, Byggnad och Mätare. Därutöver kan man lägga till generella noder för att bygga den logik man önskar.
Mätare
Energiportalen använder sig av begreppet mätare för att definiera en viss mätpunkt där förbrukning mäts. Ett mer korrekt begrepp har möjligtvis varit mätarplats men för enkelhets skull har begreppet mätare valts. Detta betyder att om man byter den fysiska mätaren men den fortfarande mäter samma förbrukning på samma plats så är det samma mätare.
Varje mätare har en tilldelad nytta och en produktionstyp (se nedan).
Undermätare
Ibland vill man dela upp en mätares förbrukning till olika nyttor eller byggnader. Det kan man göra med undermätare. Dessa utgår ifrån en huvudmätare som fördelad förbrukning räknas av ifrån. Ett exempel kan vara att vi har en fjärrvärmemätare och en mätare för värmesystemet. Då får systemet räkna ut resten, som kan betraktas som en mätare av energi till varmvatten.
- Huvudmätare
- Detta är mätaren med hela förbrukningen som skall fördelas
- Uppmätt undermätare
- En mätare som får in riktiga förbrukningar som skall avräknas från huvudmätaren
- Fiktiv undermätare
- En mätare med en beräknad förbrukning som skall avräknas från huvudmätaren
- Restmätare
- En mätare som visar återstående förbrukning från huvudmätaren efter att upmätta och/eller fiktiva mätare avräknats. Denna mätare kan visa en negativ förbrukning om mer än 100% avräknats från huvudmätaren.
Alla inblandade mätare ska ha samma produktionstyp, men de kan ha olika nyttor. Observera att huvudmätarens förbrukning inte kommer att summeras upp till byggnad och vidare, den kommer bara att kunna avläsas på mätaren själv. (Annars hade systemet ju räknat samma förbrukning två ggr.)
Byggnad
Med byggnad menas en huskropp med väggar och tak som är uppförd på en fastighet. En byggnad kan INTE sträcka sig över flera fastigheter, men det kan finnas många byggnader på en tomt. Definitionen av en byggnad skall för att kunna användas vid energideklaration följa lantmäteriets definition.
Byggnader är ett mycket centralt begrepp i Energiportalen eftersom all förbrukning på mätarnivå skall kopplas till byggnader, man kan inte följa upp förbrukning utan att definiera vilken/vilka byggnader som mätaren försörjer.
Fastighet
Med fastighet menas det juridiska begreppet fastighet, dvs. en tomt. En fastighet måste vara bebyggd med byggnader för att vara användbar i systemet. Traditionellt har man ofta följt upp energiförbrukning på fastighetsnivå men i och med införandet av energideklarationen så skall man ha uppföljning på byggnadsnivå - se nedan.
Area
Energiportalen beräknar nyckeltal för fastigheter med hjälp av area. Man kan definiera en fastighets area med hjälp av olika areabegrepp. De vanligaste är BOA + LOA, BRA och Atemp.
Operatören kan definiera vilket eller vilka areabegrepp som skall användas när man beräknar nyckeltal, såsom kWh/m² eller m³/m².
Totalarea
Totalarean är summan av alla de areatyper som ska räknas in i totalarean (enligt inställning som görs för varje areatyp). Totalarea för en mätare är summan area från de byggnader mätare betjänar i trädet. Totalarea på en byggnad är byggnadens hela area vid tidpunkten. Totalarea på en fastighet eller ett större område är summan underliggande byggnaders totalarea.
Betjänad area
Varje mätare har en betjänad area som den får från den/de byggnader som den är kopplad till.
Om flera mätare med samma nytta ligger på samma byggnad kommer dessa att dela byggnadsytan mellan sig.
Om en mätare mäter betjänar flera byggnader, blir mätarens betjänade area den sammanlagda för dessa byggnader. T.ex. om en mätare betjänar en hel fastighet med flera byggnader.
Förbrukning
Systemets fokus är att analysera förbrukningar. Systemet hanterar förbrukningar som kan hänföras till något av begreppen energi, volym och massa.
Nytta
Med nytta menas vad man använder det som förbrukas till. Ett exempel är att el kan användas till såväl belysning, som värme och kyla. Operatören kan bestämma vilka nyttor som ska finnas i systemet. Som standard innehåller Energiportalen nyttorna Värme, Kyla, Varmvatten, Kallvatten och Fastighetsel.
Varje mätare är kopplad till en specifik nytta.
Produktionstyp
Med produktionstyp menas hur nyttan åstadkoms. Exempelvis kan nyttan värme åstadkommas med olja, pellets, fjärrvärme eller el. Nyttan kyla kan åstadkommas med t.ex. fjärrkyla eller el.
Olika produktionstyper kan definieras fritt, men som standard definieras följande produktionstyper: Vatten, El, Olja, Pellets, Naturgas, Fjärrvärme och Fjärrkyla.
Varje mätare är kopplad till en specifik produktionstyp.
Kvantitet
Både produktionstyp och nytta har egenskapen "Kvantitet". Denna säger något om vad det är för typ av mätning, och vilka enheter som kan komma på fråga. För att systemet ska fungera bra ska varje mätare ha produktionstyp och nytta med samma kvantitet.
Kvantiteten avgör hur värden ska aggregeras (sammanställas) för flera mätare, och från timme till dag, dag till månad. (T ex ska en energiförbruking alltid summeras, medan en temperatur alltid ska medelvärdesbildas.)
| Kvantitet | Exempel på enhet | Aggregering över noder | Aggregering över tid |
|---|---|---|---|
| Energi | kWh | Summering | Summering |
| Volym | m3 | Summering | Summering |
| Massa | kg | Summering | Summering |
| Flöde | kW, l/s | Summering | Medelvärde |
| Siffra | °C, % | Medelvärde | Medelvärde |
Budget
Med budget menas såväl budgeterad förbrukning som budgeterad kostnad. Budgetarbetet utgår ifrån att uppskatta förbrukningar, och kostnaden blir ett resultat av förväntad förbrukning, kombinerat med de tariffer som finns inlagda.
Graddagar
Graddagar är mått på värmebehovet som SMHI definierat. SMHI levererar antalet graddagar för en viss klimatort på månadsnivå. Grovt sett är antalet graddagar summan av antalet grader under 17°C varje dag under en månad. Om det varit 15°C dygnsmedeltemperatur två dagar en månad, och samtliga andra dagar den månaden varit dygnsmedel över 17°C så har det varit 2 + 2 = 4 graddagar den aktuella månaden. Graddagar används för att normalårskorrigera värmeförbrukningsvärden, se nedan.
Energiindex
Energiindex är ett förbättrat mått på värmebehov som SMHI levererar. Fyller samma behov, och uttrycks, som graddagar men tar även hänsyn till vind och sol.
Normalår
Normalår definierar antal graddagar (eller energiindex) som är ett "normalt år". För närvarande definieras ett normalår som genomsnittet av hur vädret varit 1981 -- 2010 på den aktuella platsen.
Normalårskorrigerad förbrukning
Normalårskorrigerad förbrukning beräknas för att korrigera en förbrukning, så att den skall kunna jämföras med ett "normalt år" klimatmässigt (enligt definition ovan). Detta ger en mycket mer rättvis jämförelse mellan förbrukningar för olika år. Man kan normalårskorrigera med hjälp av graddagar eller energiindex.
Effektsignatur
En effektsignatur beräknas utifrån ett prickdiagram där genomsnittseffekt som använts för att värma upp en byggnad matchas med den utetemperatur det dygnet. För att kunna skapa en effektsignatur krävs information om såväl energiförbrukning varje dygn som utetemperatur aktuellt dygn. Effektsignaturen beräknas utifrån förutsättningen att varje byggnad har en brytpunkt där uppvärmning behövs som ligger i intervallet 10°C till 20°C.
Effektsignaturen ger en bild av hur byggnaden uppför sig i olika väderleks-förhållanden.
Estimerade förbrukningar
Med estimerade förbrukningar menas en "gissning" på vad förbrukningen är när vi saknar information. Estimering görs endast för månadsvärden. Estimering görs utifrån samma period föregående år. Beroende på inställning på mätare och nytta räknas förbrukningen om enligt normalårsprincipen.
Prognos
Med prognos menas en estimerad förbrukning som ligger i framtiden. Det innebär t.ex. om man befinner sig i mitten av maj, men bara har fått in mätvärden t.o.m. mars, så är aprilförbrukningen estimerad, men maj-decemberförbrukningen är en prognos.
Tariff
En tariff är en viss kostnad som uppstår i samband med att man förbrukar t ex energi eller vatten. Kostnaden kan bestå av "ekonomisk kostnad" i kr, men även olika typer av miljöpåverkande utsläpp, t.ex. CO².
Parameter
En parameter är en extra dataserie för en mätare. Exempelvis kan vi lagra temperaturen på en fjärrvärmemätare. Parametrar används ofta i tariffberäkningar. Ett parametervärde vars tidstämpel är 2017-01-01 är giltigt från denna tidpunkt och tillsvidare eller tills nästa värde. T.ex. värde 100 på datum 2017-01-01 och värdet 200 på datum 2018-01-01. Då är värdet på parametern 100 mellan 2017-01-01 till 2018-01-01 och därefter 200.
Administration (CMT)
Import
Importmoduler konfigureras i Data Field Imports som finns under Datakälla > Entities. Dessa moduler importerar data från filer. Olika moduler hanterar olika filformat.
Tillgängliga moduler är:
-
Consumption File Import
-
Invoice Filed Import
-
Mätare Parametrar Field Import
-
SMHI Klimatdatafält Import
-
XML File Import
Varje modul kan konfigureras med:
-
Vilken katalog som övervakas för inläsning av filer
-
Tidsupplösning för importerad data
-
Vilken Fältsänka importerad data skall lagras i
Vissa moduler kan ha fler konfigureringsmöjligheter. Dessa beskrivs i detalj senare.
Konfigurerade importer övervakar kontinuerligt konfigurerad katalog och importerar nya filer omgående.
Summera förbrukningar - Tidsperiod
Summering av förbrukningar görs av en fält processor som körs av ett Field Sink Read Job. För denna summering används en processor av typen Analyser Consumption Aggregation FieldProcessor. Processorer konfigureras i Data Field Processors som finns under Datakälla > Entities.
Processorn konfigureras med:
-
Källans tidsperiod (Timma, Dag, Månad, etc.)
-
Målets tidsperiod (Timma, Dag, Månad, etc.)
Jobbet konfigureras med:
-
Källfältsänka för data att bearbeta
-
Destinationsfältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerad intervall.
Alla data som jobbet levererar till processorn som matchar konfigureringen för källans tidsperiod konverteras till målets tidsperiod och levereras tillbaka till jobbet. Ett jobb med en egen processor konfigureras för varje periodicitet som önskas summeras. T.ex.: Timma till dygn eller dygn till månad.
Normalårskorrigera data
Normalårskorrigering av förbrukningar görs av en jobbtyp som kallas Field Sink Read Job. För normalårskorrigering används en processor av typen Analyser Klimat Korrigerad Förbrukning Calculator. Processorn konfigureras i Data Field Processors som finns under Datakälla > Entities.
Processorn konfigureras med:
-
Källa för klimatdata. (Ställs in i Analyser->Inställningar)
-
Kryssruta "Refresh ClimateData on Start". Om ikryssad läses klimatdata in varje gång jobbet körs. Detta innebär en viss prestandaförlust, annars hålls data i minnet mellan körningarna.
Jobbet konfigureras med :
-
Käll-fältsänka för data att bearbeta
-
Destinations-fältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerat intervall.
För att jobbet ska kunna köras krävs att ingående fastigheter har klimatzon inställd, och att det finns klimatdata importerad för hela året.
Jobbet hämtar in klimatdata och förbrukningsdata från käll-fältsankor, bearbetar och skriver resultatet till destinationsfältsänkan. Utdata får ett tillägg i fältnamnen ", ClimateCorrected".
Se bilaga 1: Normalårskorrigering.
Estimera förbrukningar
Estimering och prognos görs i systemet på samma sätt. Skillnaden är att prognos är för framtida data, estimering är för historiska data som av någon anledning inte (ännu) fyllts på med mätt data.
Prognos av förbrukningar görs av en jobbtyp som kallas Field Sink Read Job. För prognostisering används en processor av typen Analyser Prognosis Calculator. Processorer konfigureras i Data Field Processors som finns under Datakälla > Entities.
Processorn konfigureras med:
-
Källa för klimatdata. (Ställs in i Analyser->Inställningar)
-
Checkbox: ska nya fält skapas. Om ikryssad skrivs estimerade värden till ett separat fält. I annat fall skrivs de till samma fält som importerad data (men eventuell befintlig importerad data skrivs inte över).
-
Börja från och Generera till: Vanligtvis genereras estimerad data från början av nuvarande månad, fram till slutet av nästa år. Om annat tidsintervall önskas kan detta ställas in här.
Jobbet konfigureras med:
-
Käll-fältsänka för data att bearbeta
-
Destinations-fältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerad intervall.
Estimeringen görs utifrån data från föregående år, antingen genom att använda samma värde, eller genom att räkna om utifrån de väderdata som finns, beroende på inställningar på mätare (metoder för uppskattning och klimatkompensering), nytta (Normalårskorrigering) och byggnad (Andel varmvatten). Om väderdata för skriven tid finns tar systemet också hänsyn till den.
För att väderdata ska påverka estimeringen krävs att Uppskattningsmetoden är satt till "NormalYear" OCH att Klimatkorrigeringsmetod är normalårskorrigering (antingen för att det ärvs från nyttan eller för att det är inställt på mätaren).
Summera förbrukningar - Position i träd
Summering av förbrukningar görs av en fältprocessor som körs av ett Field Sink Read Job. För denna summering används en processor av typen Analyser Consumption Summary Calculator. Processorer konfigureras i Data Field Processors som finns under Datakälla > Entities.
Processorn konfigureras med:
- Tidsperiodtyp (Timma, Dag, Månad, etc.)
Jobbet konfigureras med :
-
Käll fältsänka för data att bearbeta
-
Destinations fältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerad intervall.
Alla data som jobbet levererar till processorn som matchar processorns Tidsperiodtyp summeras och levereras tillbaka till jobbet. Ett jobb med en egen processor konfigureras för varje periodicitet som önskas summeras. T.ex.: Dygnsvärden eller månadsvärden.
Beräkna kostnader
Kostnadsberäkningar görs av en fältprocessor som kallas av ett Field Sink Read Job. För kostnadsberäkningar används en processor av typen Analyser Cost Calculator. Processorer konfigureras i Data Field Processors som finns under Datakälla > Entities.
Jobbet konfigureras med :
-
Käll-fältsänka för data att bearbeta
-
Destinations fältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerad intervall.
En förutsättning för att kunna beräkna kostnader för en mätare är att denna är kopplad till en tariff och har nytta samt produktionstyp definierat.
Processens resultat är kostnader per tariff och tidsperiod.
Summera kostnader
Grunder
Kostnadssummering görs av en fält processor som kallas av ett Field Sink Read Job. För kostnadsberäkningar används en processor av typen Analyser Total Cost Calculator. Processorer konfigureras i Data Field Processors som finns under Datakälla > Entities.
Jobbet konfigureras med :
-
Käll fältsänka för data att bearbeta
-
Destinations fältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerad intervall.
Processorn summeras alla kostnader för en mätare. Alla löpande kostnader läggs ihop till Total löpande. Alla fasta avgifter läggs ihop till Total fast kostnad. Sedan räknas en summa fram för totalen.
Fördela kostnader
Konstnadsfördelning görs av en fält processor som kallas av ett Field Sink Read Job. För konstnadsfördelning används en processor av typen Analyser Cost Summary Calculator. Processorer konfigureras i Data Field Processors som finns under Datakälla > Entities.
Jobbet konfigureras med :
-
Käll fältsänka för data att bearbeta
-
Destinations fältsänka för bearbetad data
-
Urvalsfunktion för att filtrera ut specifik data från källan om så önskas
-
Schemaläggare för att köra jobbet per automatik med konfigurerad intervall.
Processorn summerar olika kostnader från underliggande mätare till byggnader, fastigheter och noder högre upp i trädet. Summor skapas för varje produktions typ, nytta och kombination därav. Kostnader från mätare som betjänar flera byggnader delas upp proportionellt beroende på byggnadernas area. Om en byggnad betjänas av flera mätare av samma produktionstyp och nytta så adderas de kostnaderna till byggnadens area.
Konfigurera larmfunktioner
I Energiportalen finns möjlighet att skapa förbrukningslarm. Olika typer av larmfunktioner skapas i CMT beroende på vilken typ av larm som önskas i systemet. Larmfunktionerna kan vara absoluta eller som procentuell förändring jämfört med verklig förbrukning. I larmfunktionen väljs också vilken period som funktionen skall jämföras emot: timmar, dag, månad, kvartal, tertial eller år. Ett jobb skapas sedan per automatik som i sin tur exekverar larmfunktionen. Exekveringstid kan justeras efter behov.
När larmfunktionen är skapad kommer denna att bli tillgänglig i webinterfacet.
Skapa larmfunktion
Öppna datakällan Dataprocessorer som finns under Entiteter.
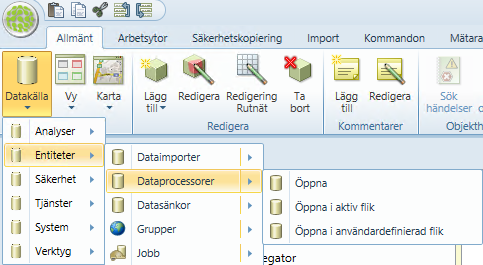
Lägg till ny processor av typen: Analyser Förbrukning Larm FältProcessor.
I fönstret som öppnas fyller man i följande:
-
ID: Namn som syns i webgränssnitt.
-
Beskrivning: Förklarande text som syns i webgränssnitt. Det är lämpligt att här få med vilken enhet gränsvärdet förväntas ha.
-
Period typ: Upplösning på värden som skall utvärderas.
-
Larm beräkningsuttryck: Formeln som beräknar larmet (se exempel nedan).
-
Larm Text: Kan lämnas tomt.
-
Källtyp: Typ av data som larmet övervakar.
-
Per m2<\sup>: Kryssas i om givet värde ska vara per kvadratmeter, inte absolutvärde.
-
Offset: Om larm ska utlösas av förändring i värde, ange tidsskillnad mellan jämförda värden, Periodtyp och antal (t ex Månad och 3 för tre månader).
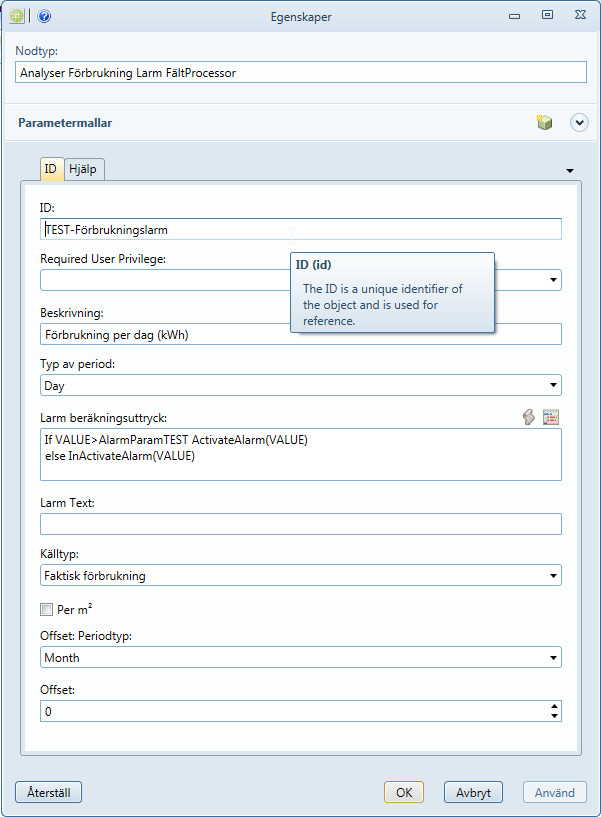
Avluta med OK så finns din nya larmfunktion tillgänglig i webgränssnittet.
Exempel på larmfunktion "höglarm"
IF VALUE > HögGräns ActivateAlarm(VALUE) ELSE InActivateAlarm(VALUE)
-
I denna funktion används HögGräns som användarinställd parameter. Den skapas automatisk första gången som en larmregel skapas med denna funktion vald.
-
Parametern VALUE motsvarar alltid det aktuella värdet den aktuella månaden.
-
ActivateAlarm(VALUE) är en funktion som skapar ett larm.
-
InActivateAlarm(VALUE) är en funktion som försöker återställa ett larm.
Uttrycket ovan kontrollerar om VALUE är större än HögGräns. Om det är sant så aktiveras ett larm. Annars så inaktiveras larmet.
Exempel på larmfunktion på ökning i %
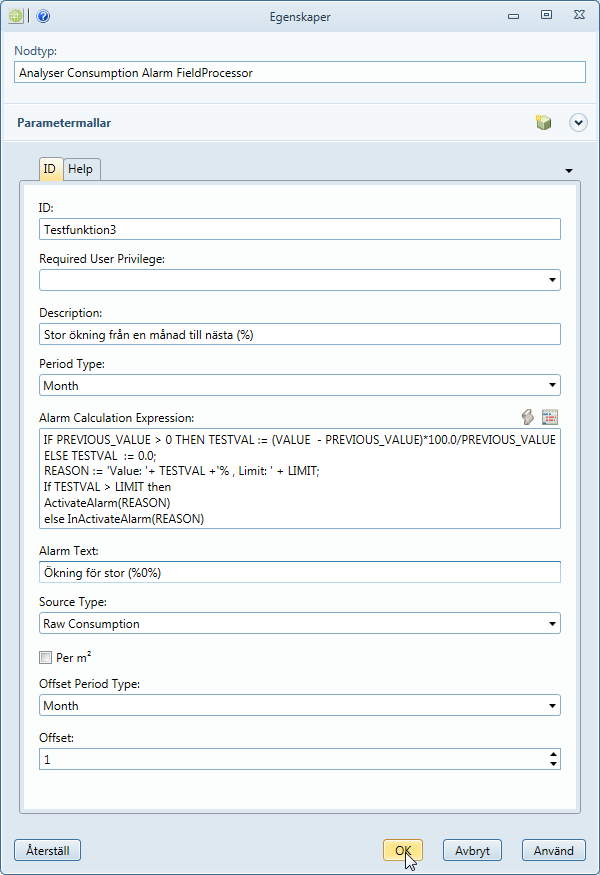
Man kan konfigurera larm som jämför aktuellt värde med ett tidigare. Om värdet i "Offset" inte är 0, blir värdet "PREVIOUS_VALUE" tillgängligt i skriptet, värdet vid jämförelsetidpunkten (som alltid är före aktuell tidpunkt).
IF PREVIOUS_VALUE > 0 THEN TESTVAL := (VALUE - PREVIOUS_VALUE)*100.0/PREVIOUS_VALUE
ELSE TESTVAL := 0.0;
REASON := 'Value: '+ TESTVAL +'% , Limit: ' + LIMIT;
If TESTVAL > LIMIT then
ActivateAlarm(REASON)
else InActivateAlarm(REASON)
-
Om inställningen Offset är annat än noll kan jämförelse med tidigare göras. Då betyder PREVIOUS_VALUE det äldre värdet att jämföra mot.
-
I det här skriptet räknar vi om de olika förbrukningarna till en förändring i procent.
Exempel på larm för förbrukning vid specifika klockslag
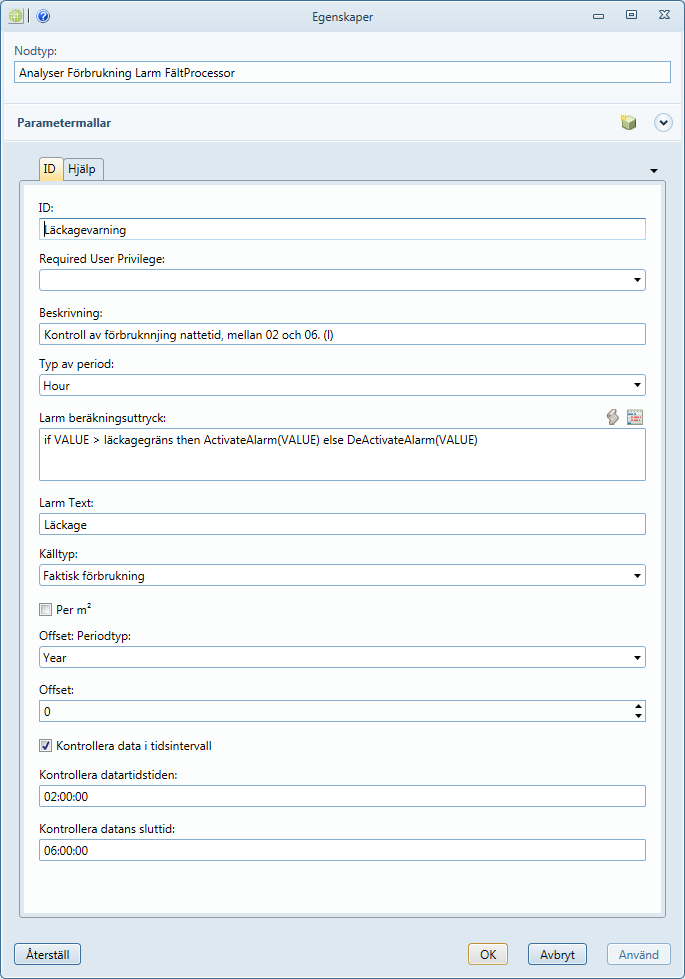
Om periodtypen sätts till timmar, visas kryssrutan "Visa data i tidsintervall". Med den ikryssad kan man välja en tidsperiod på dygnet då kontroll av förbrukning ska göras. Utanför de givna klockslagen ignoreras förbrukningen. Tänkt t ex för läckagelarm.
Modulbeskrivningar
Topologi
I datakällan Topology finns tre noder:
Analyser Climate Data Root
Här sparas klimatdata för de noder som specificerats i datakällan Climate Zones.
Analyser Meters Root
Här sparas mätare och dess specifika inställningar. Det är också här man lägger till mätare manuellt. Hierarkisk skapas mätare alltid under en kundnod och förslagsvis även under en produktionstyp nod.
Analyser Summary Nodes Root
Här sparas uppsummerad data för alla noder för respektive kund
Data Field Imports
Generellt om importer
Alla importer övervakar en katalog och importerar alla filer som matchar importens filter. Filer som systemet lyckas importera tas bort. Om en fil misslyckas så läggs filen i en underkatalog till den övervakade katalogen. Katalogen heter failed och filen flyttas dit. Motsvarande sker med lyckade importer. När filen är inläst så läggs den i en underkatalog till den övervakade katalogen. Katalogen heter i detta fallet completed och filen flyttas dit. Notera att en fil som går att läsa men där det finns rader som inte matchar någon nod i systemet anses som lyckade importer.
Vanliga inställningar:
-
Search filter: Filnamnsfilter. T.ex: *.csv för att importera alla csv-filer.
-
Input folder: Katalogen som importmodulen skall övervaka/söka i.
-
Files encoding: Textformat. Detta är viktigt om filen innehåller åäö eller andra specialtecken. Vanligtvis används utf-8 eller windows-1252 (windows-1252 är oftast kompatibelt med ANSI)
-
Sinks that will receive processed fields: en pekning till den databas som importerad data skall lagras i.
Consumption
Denna importmodul läser förbrukningar från filer i formatet Consumption_01:
<mätarId><\tab><förbrukningsTyp><\tab><startDatum><\tab><slutDatum><\tab><förbruking><\tab><enhet><\tab><status>
Exempel:
30000173 FV 2013-01-01 00:00:00 2013-01-01 01:00:00 460 kWh 1
Kolumnerna är tabbavgränsade. Där första kolumnen är ett unikt mätarId. En mätare med samma id måste finnas för att data skall importeras. Endast en mätare med samma id får finnas då importen endast lagrar data på den första mätaren som hittas.
Importmodulen måste konfigureras med vilken periodicitet importerad data inkommer med. Timvärden, dygnsvärden eller månadsvärden.
Invoice
Denna importmodul läser kostnader från filer i följande format:
<mätarId><\tab><mätarNummer><\tab><startDatum><\tab><slutDatum><\tab><kostnadsTyp><\tab><kostnad><\tab><status>
Exempel:
20410032 450755338628 2015-01-01 2015-02-01 Elnät - Energiavgift 24364,357 1
Kolumnerna är tabbavgränsade. Där första kolumnen är ett unikt mätarId. Den femte kolumnen är kostnadstypen. Denna kostnadstyp måste vara definierad i systemet för att data skall importeras.
Modulen skall med en checkbox konfigureras för om importerad data är inklusive moms eller inte.
Parameters
Denna importmodul läser parametrar från filer i följande format:
<mätarId><\tab><parameterNamn><\tab><datum><\tab><värde>
Exempel:
30000173 Toppeffekt 2013-08-01 1053
Kolumnerna är tabbavgränsade. Där första kolumnen är ett unikt mätarId. Den andra kolumnen är parameternamnet. Detta parameternamn måste vara definierad i systemet för att data skall importeras. Att en parameter är definierad innebär att den finns konfigurerad med samma namn som i filen i datakällan Parametrar.
SMHI
Denna importmodul läser klimatadata från filer i följande format:
<ortsId>;<ort>;<datum>;<graddagarAkt>;<energiindexAkt>;<uteTempAkt>;<graddagarNorm>;<energiindexNorm>;<uteTempNorm>
Exempel:
102023;Abisko;201501;1058;852;-10.5;1060;817;-9.4;
Kolumnerna är ;-avgränsade. Den första kolumnen är SMHIs ort-Id. Orten måste vara definierad i systemet för att data skall importeras. Definierade orter finns i Topology datakällan.
Exempel:
7142 Göteborg A - Graddagar 2016-09-03 16.8
Kolumnerna är mellanslagavgränsade. Den första kolumnen är SMHIs zonId. Zonen måste vara definierad i systemet för att data skall importeras.
Importmodulen måste konfigureras med vilken periodicitet importerad data inkommer med. Timvärden, dygnsvärden eller månadsvärden.
Data Field Sinks
Generellt
Applikationen använder sig av en eller flera fältsänkor för att spara persistent data. En fältsänka är en generell mappning till ett lagringssystem. Olika fältsänketyper kan användas för att spara data i t.ex. filer eller databaser av olika fabrikat.
Vilken fältsänka som används för vilken typ av data konfigureras under Data Source > Analyser > Settings
Remote MS SQL Server Database
Fältsänketypen Remote MS SQL Server Database läser och skriver till en databas på en instans av MS SQL Server.
Inställningar:
-
Idle timeout (ms): Hur länge anslutningen till SQL-instansen skall vara aktiv efter senaste användande.
-
Table partitions: Hur många tabeller data skall dela upp i för att fördela last.
-
Check Field Status Priorities when saving data: Hurvida fältsänkan skall avgöra om data får skrivas över.
-
Check statuses mode: Inställning för hur status hanteras. Skriv över om > tidigare status eller Skriv över om >= tidigare status .
-
Host Name: Adressen till SQL-instansen.
-
Database Name: Namn på databasen på SQL-instansen.
-
Create database if one is not found: Om databasen skall skapas om den inte finns på SQL-instansen.
-
User Name: Användarnamn för kontot till SQL-instansen.
-
Password: Lösenord för kontot till SQL-instansen.
Jobb
Data importeras i systemet då datafiler läggs i importkatalogen. I stort sett all annan datahantering görs i det vi kallar jobb. Schemalagda sekvenser av (oftast) läsning-beräkning-skrivning.
Jobb konfigureras i datakällan Jobb.
Schemaläggning
Jobb körs på förutbestämda tider eller med förutbestämda intervall. Schemaläggningen konfigureras under fliken "Execution". För en jobb-sekvens görs schemaläggningen i själva sekvensen, inte på de enskilda jobben.
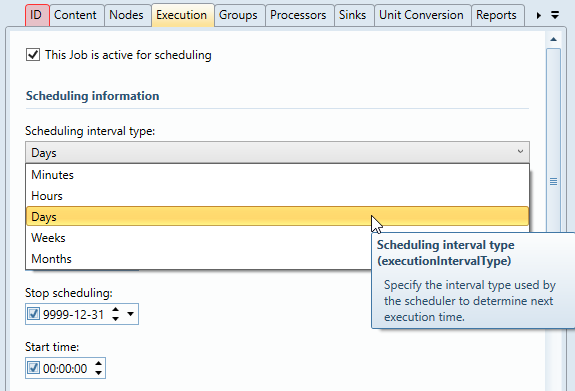
Jobbet aktiveras med check-ruta "This job is active for scheduling". Om rutan inte är ifylld kan jobbet ändå köras manuellt.
Intervall
Jobbet körs med vissa intervall. Man kan välja vilken enhet som används för intervallet. Beroende på vald enhet beter sig schemaläggningen något olika.
Minutes, Hours: Bara tidsintervall. Jobbet upprepas med valt intervall.
Days: Om man väljer intervall 1 dag fås möjligheten att exkludera veckodagar. Annars samma beteende som för minut och timma.
Weeks: Jobbet kommer att köra med angivet antal veckor emellan, på den veckodag och tid som anges i "Start scheduling"
Months: Man får möjlighet att välja om jobbet ska köras med samma avstånd till början på, eller slutet av månaden. Väljer man början innebär det alltid samma datum. Väljer man slutet kan det t ex bli om schemaläggning startar 27 januari, så körs jobbet nästa gång 24 februari, 27 mars, 26 april, osv. Alltid med lika många dagar kvar av månaden.
Mer schema
Om man öppnar ett befintligt jobb och ändrar någon tidsinställning, fås check-rutan "Reset scheduling of the job". Om den är ikryssad då man trycker OK görs en ny evaluering av nästa körtillfälle, utifrån inställningar för intervall och starttid. Detta gäller om vald starttid ligger i framtiden.
"Retry": Om jobbet av någon anledning inte kan slutföras kan man få det att försöka igen. Siffran 0 ger inga omförsök, och är ofta att föredra, beroende på vad jobbet gör. Annars ska man vara uppmärksam på att omförsöken inte ska riskera att hålla på till nästa ordinarie exekvering.
Gemensamma jobb
Meter Area Calculator
Detta jobb kör processorn Analyser Meter Area Calulator för att beräkna varje mätares area som ärvs från knutna byggnader. Det används för att åtgärda felaktiga eller saknade areor på mätare.
Served Area Summary Calculator
Detta jobb kör processorn Analyser Served Area Summary Calulator för att beräkna varje mätares area som ärvs från knutna byggnader. Det används för att åtgärda felaktiga eller saknade areor på mätare.
Power Signature Calculator
Detta jobb kör processorn PowerSignatureCalculation för att beräkna effektsignatur. Jobbet är kopplat till rapporten Effektsignatur.
Standard jobbsekvens för en kund
1. Consumption Hour -> Day
Detta jobb summerar timförbrukningar till dygnsförbrukningar. Systemet förväntar sig kvalitetssäkrad data utan luckor och skapar ingen dygnsförbrukning om någon timma saknas.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
2. Consumption Day -> Month
Detta jobb summerar dygnsförbrukningar till månadsförbrukningar. Systemet förväntar sig kvalitetssäkrad data utan luckor och skapar ingen månadsförbrukning om något dygn saknas.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
3.1. Split Month Consumption for sub-meters
Detta jobb beräknar hur mycket förbrukning varje undermätare får från sin huvudmätare.
Beräkningen görs endas på månadsvärden. Beräkningarna körs på mätare under kopplad topologi nod (under grenen Analyser Meters Root). Resultatet sparas per mätare.
3.2. Split Day Consumption for sub-meters
Detta jobb beräknar hur mycket förbrukning varje undermätare får från sin huvudmätare.
Beräkningen görs endas på dygnsvärden. Beräkningarna körs på mätare under kopplad topologi nod (under grenen Analyser Meters Root). Resultatet sparas per mätare.
3.3. Split Hour Consumption for sub-meters
Detta jobb beräknar hur mycket förbrukning varje undermätare får från sin huvudmätare.
Beräkningen görs endas på timvärden. Beräkningarna körs på mätare under kopplad topologi nod (under grenen Analyser Meters Root). Resultatet sparas per mätare.
4. Consumption Month Climate Correction
Detta jobb korrigerar förbrukningar med klimatdata från SMHI.
Jobbet kräver att det finns ett helt år med klimatdata för att leverera resultat. Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
5. Consumption Month Estimation
Detta jobb prognostiserar framtida förbrukningar för innevarande och nästkommande år.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
5.1. Consumption Month Climate Correction for Estimation
Detta jobb utgår ifrån de prognostiserade fälten, och korrigerar dessa utifrån klimatdata från SMHI.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
6. Consumption Month Summary
Detta jobb summerar månadsförbrukningar från mätare till noder högre upp i trädstrukturen.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per summeringsnod.
7. Consumption Day Summary
Detta jobb summerar dagsförbrukningar från mätare till noder högre upp i trädstrukturen.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per summeringsnod.
8.1 Total Cost Calculation by Tariffs
Detta jobb beräknar månadskostnader för en mätares förbrukning utifrån kopplade tariffer.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
8.2 Total Cost Calculation
Detta jobb summerar totala månadskostnaden för en mätare. Den tittar på kostnader beräknade i föregående steg. Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per mätare.
8.2.1. Total Cost Vat Calculation
Detta jobb beräknar kostnad med eller utan moms, beroende på vilket som redan finns från tidigare steg, alternativt är importerat. Efter att jobbet körts ska det för varje månad finnas kostnad både med och utan moms.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per summeringsnod.
8.3 Cost Month Summary
Detta jobb summerar månadskostnaden från mätare till noder högre upp i trädstrukturen.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per summeringsnod.
9. Consumption Hour Summary
Detta jobb summerar timförbrukningar från mätare till noder högre upp i trädstrukturen.
Beräkningarna körs på undernoder till kopplad gupp nod. Resultatet sparas per summeringsnod.
10. Property Index Calculation
Detta jobb räknar ut Fastighetsindex på alla noder i systemet. Resultatet sparas per summeringsnod.
Analyser-specifika datakällor
Produktionstyper
I denna datakälla definieras produktionstyper. En produktionstyp beskriver vad som köps från leverantören. T.ex. köps fjärrvärme för uppvärmning. Då är produktionstypen fjärrvärme. Varje mätare i systemet skall ha en produktionstyp.
Inställningar:
-
Shortname: Förkortning av namnet. T.ex. FV för fjärrvärme. Detta visas i webbgränssnittet och används i bl.a. tariffer.
-
Name: Namn på produktionstypen. T.ex. fjärrvärme. Detta visas i webbgränssnittet.
-
AnalyserId: Används endast vid import från ManodoServer.
Nyttor
I denna datakälla definieras nyttor. En nytta beskriver hur förbrukningen använts. Varje mätare i systemet skall ha en nytta.
Inställningar:
-
Shortname: Förkortning av namnet. T.ex. KY för kyla. Detta visas i webbgränssnittet.
-
Name: Namn på nyttan. T.ex. kyla. Detta visas i webbgränssnitt.
-
Background icon color: Bakgrundsfärg för ikonen i webbgränssnittet.
-
Estimation setting: Hur prognoser skall beräknas. Likt föregående år eller likt ett normalår.
-
AnalyserId: Används endast vid import från ManodoServer.
Leverantör
I denna datakällakälla definieras leverantörer. Dessa används av tariffer för att skilja på t.ex. el-avgifter från olika bolag.
Kostnadstyper
I denna datakälla definieras kostnadstyper. Dessa används av tariffer för att avgör hur kostnaden beräknas.
Inställningar:
-
Name: Namn på kostnadstypen. Kommer att visas som val i tariffer samt användas vid import av kostnader.
-
Class: Definierar typ av kostnad. T.ex. fast, rörlig eller miljöpåverkan.
-
Production Type: Begränsar vilka mätartyper som kostnadstypen gäller. T.ex. el eller fjärrvärme.
-
Exclude from Total Cost: Hurvida kostnaden skall inkluderas när totalkostnad summeras.
Tariffer
I denna datakälla definieras tariffer som sedan kan knytas till mätare för att beräkna kostnaden för förbrukningen.
Först definieras en tariff.
Inställningar:
-
Name: Namn på tariffen. Detta kommer att visas i kostnadsvyer.
-
Supplier: Leverantör av media. T.ex. olika bolag som levererar el
-
Costtype: Vilken kostnadstyp tariffen gäller. T.ex. Fast kostnad för el.
-
Fixed/Running cost, Kr per: Skalning för tariffberäkning. Om kostnadstypen är fast så väljs periodiciteten för kostnaden. Om kostnadstypen är rörlig så väljs storheten som kostnaden multipliceras med. T.ex. kWh eller m3.
För varje tariff skapas en eller flera tidsperioder då ett visst pris gäller:
-
Valid from: Första datum som priset gäller.
-
Valid to: Sista datum som priset gäller. Kan lämnas tomt om priset gäller tills vidare.
-
Cost per kWh/m3/Month: Enhets pris. Om kostnaden beräknas per förbrukad enhet eller period så sätt det priset här. Enheten eller perioden kommer från tariffen.
-
Script: Om prisskalan är bruten eller kostnaden beräknas på annat mer avancerat sätt så skriv en formel för detta här. Syntax för skriptet beskrivs i kapitel Exempelkonfiguration.
Flera tariffer kan grupperas. Välj att skapa en ny nod.
-
Välj nodtypen Tariff Group Node.
-
I fönstret som dyker upp fyll i följande:
-
ID: Visningsnamn för tariffen. T.ex. Grupp energikostnader.
-
Tariffs: Lägg till de tariffer som skall ingå i gruppen.
-
Mätare tariffer
I denna datakälla skapas knytningar mellan mätare och tariffer. Automatiskt skapas det en koppling till alla tariffer som finns i datakällan tariffer.
Under varje tariff skapas en eller flera tidsperioder då en koppling till en eller flera mätare gäller:
-
Start date: Första datum då kopplingen gäller.
-
Stop date: Sista datum då kopplingen gäller.
-
Groups to include to tariff: Välj in de grupper med mätare som skall kopplas.
-
Nodes to include to tariff: Välj in de individuella mätare som skall kopplas.
Till tidsperioden kopplas antingen individuella mätare eller grupper med referenser till flera mätare. Tariffen appliceras bara på mätare med samma produktionstyp som kostnadstypen i tariffen. Således går det att skapa en referens till hela kundgruppen även om de har olika mätare av olika produktionstyper.
Skapa kund
Följande kapitel beskriver hur man skapar en kund via import eller helt ny.
Kapitlen är organiserade enligt nedan:
-
hur du importerar en kund från Analyser3. Detta inkluderar:
-
Kundens träd
-
Byggnadsareor
-
Byggnadstyper
-
Kundens mätare
-
Produktionstyper
-
Nyttor
-
Leverantörer
-
Areatyper
-
-
hur du skapar en ny kund från grunden. Detta motsvarar import av kund.
-
hur du beräknar areor som andra jobb behöver.
-
hur du skapar allt relaterat till kostnader för kunden.
-
hur värden importeras.
-
hur du kör en kunds beräkningar.
Importera från Analyser 3
Förutsättningar
För att kunna importera en kund från Analyser 3 så måste vi ha tillgång till databasen [manododb3] uppsatt på en MS SQL servern som applikationen kan ansluta till.
Konfigurera kund
-
Öppna datakällan Analyser > Customers.
-
Välj att skapa en ny nod.
-
Välj nodtypen Customer node.
-
På fliken ID:
-
Customer name: Ange önska kundnamn för KTCServer. Detta kommer kunden att använda för att logga in.
-
Required User Privilege: Lämnas tom. Fätet fylls automatiskt när noden sparas.
-
GUI Skin: Fylls i om man vill använda annat än standard färgtemat.
-
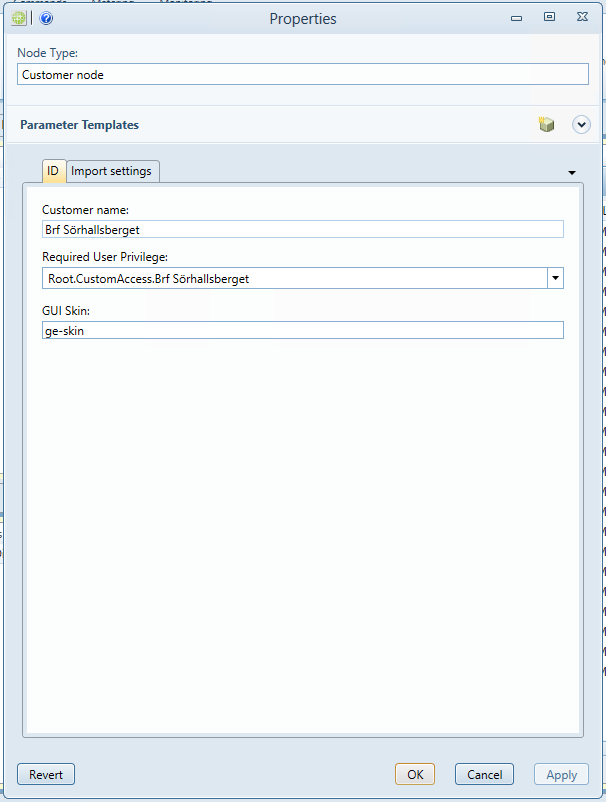
-
Klicka på OK för att spara kunden.
-
Högerklicka på den nya kund noden och välj Import from Analyser.
-
I fönstret som dyker upp fyll i följande:
-
External ID: Kundens ID i Analyser3. Värdet från databasen i tabellen Usr.Customer.
-
ConnectionString: Anslutningsuppgifter för databasen Manododb3.
- T.ex: "data source=servernamn; user id=användarnamn; pwd=lösenord; persist security info=False; Application Name=KTC Server; initial catalog=databas; Asynchronous Processing=true"
-
Generate default calculation job sequence: Om aktiverad så skapas beräkningsjobb specifikt för denna kund I modulen jobb.
- Om man inte skapar jobben här i importen så finns möjligheten att skapa dessa senare. Jobben skapas då genom att högerklicka på kund noden och välja generate analyse calculation jobs eller alternativt välj Attach to existing jobs.
-
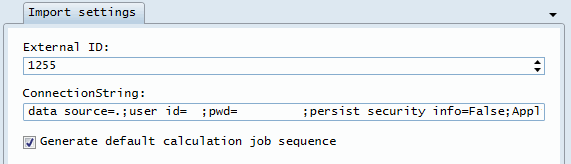
-
Klicka på OK för att påbörja importen.
-
Efter importen kommer det upp ett informationsfönster med resultatet.

-
Kontrollera om meddelandet innehåller varningar om mätardubbletter.
-
Om det finns dubbletter så importeras bara första träffen. Flera mätare med samma id importeras inte.
-
Om det finns en varning så kan man söka i händelseloggen efter varningar för att se vilka mätare som måste kopplas för hand.
-
-
Kontrollera i Gruppstruktur och Topologi så att inga noder har varningar.
- Exempel på varning kan vara att mätare saknar area.
-
Importen skall ha skapat all struktur som behövs för att hantera förbrukningar. För att hantera kostnader så måste fler datakällor konfigureras för kunden.
Skapa ny kund manuellt
Skapa den nya kunden i datakällan Analyser->Kunder. Ge kunden ett namn. Detta ska sedan användas vid inloggning.
Skapa mätare
Om man har mätinsamling direkt från systemet, så kan man använda t ex MBus-noderna som de är. Man behöver dock fylla i under fliken "Analyser" på samma sätt som för de interna mätarna (se nedan).
Om installationen ska arbeta med importerad data, sätts mätare upp som interna mätare. Dessa läggs lämpligen i en egen hierarki i topologiträdet.
Då kunden skapas, skapar systemet automatiskt en sorteringsnod i Topologi, under "Analyser Meters Root". Under denna bör man sedan skapa en sorteringsnod för varje produktionstyp man ska använda. Annan sortering går också bra tekniskt, men på detta sätt ansluter man sig till hur de automatiskt konfigurerade kunderna (de som importeras från äldre verktyg för energiuppföljning) byggs upp. Exempel:
Skapa en sorteringsnod genom att markera kundnoden, och Lägg till->"Production type virtual node". Det räcker att fylla i namn, lämpligen enligt exemplet ovan.
Markera önskad sorteringsnod, välj Lägg till->Meter.
Ge mätaren ett ID. Observera att det för mätarställningar är detta som används då importerad data ska placeras på rätt mätare, så ID måste stämma med i importfiler angivet ID. ID måste också vara unikt för hela systemet.
Beroende på vilken typ av dataimport som ska göras, kan man behöva fylla i fältet "Meter Location Id". För förbrukningsimporter är det detta fält som ska stämma med importfilen.
På fliken "Analyser" behöver man fylla i:
-
Uppskattningsmetod. LastYear för sådant som inte kan förväntas variera p g a väder. NormalYear för förbrukningar kopplade till uppvärmning.
-
Startdatum: Datum för äldsta förväntade mätardata.
-
Nytta. Väljs från de nyttor som tidigare konfigurerats i systemet. Om nyttan ännu inte finns, så kan man med ett högerklick också skapa en ny.
-
Produktionstyp. Väljs bland de produktionstyper som tidigare skapats i systemet.
Mätargruppnod
Efter att mätare är skapade enligt ovan har du möjlighet att gruppera mätare i vad vi kallar en "mätargruppnod". Detta är smidigt och tidsbesparande när man exempelvis vill knyta många mätare till en och samma tariff eller tariffgrupp.
-
Markera "Customer topology node"och välj att lägga till en "Mätar grupp nod".
-
Lägg till de mätarreferenser som du vill skall ingå i gruppen under fliken "noder".
Skapa fastighet
I datakällan Entiteter->Grupper bygger man upp kundens fastighetsbestånd på det sätt som är logiskt för aktuell kund. Bygg på under den kundreferens som skapats automatiskt. Man kan arbeta med land, region, stad, område, gata, osv. Allt det är frivilligt, och det avspeglas i navigeringsträdet som användaren ser.
Vad som dock behövs är Fastighet. Alla byggnader hör hemma i fastigheter.
Skapa en fastighet, "Estate", och ställ in ID. Om man inte vill att ID ska visas för användaren, så kan man i fältet Namn fylla i önskat visningsnamn. ID måste vara unikt i systemet, det behöver inte namn vara.
På fliken Analyser, välj Klimatzon (behövs för normalårskorrigering), och i förekommande fall, Väderstation(behövs för att beräkna effektsignatur).
Skapa byggnader
Under fastigheten kan man skapa byggnader.
Skapa byggnad, ställ in ID. Som på fastighet kan man också välja att fylla i Namn.
På Analyser-fliken, ställ in Varmvattenandel till ett tal mellan 0 och 1. Om det kommer en fjärrvärmemätare kopplad till byggnaden, antas denna andel av energin användas till att värma varmvatten. Finns det separat mätning av energi till varmvatten, ska denna siffra sättas till 0.
Konfigurera koordinater på byggnader
Med valfri karttjänst (t ex hitta.se eller maps.google.com) kan man få fram exakt latitud och longitud, på formen 57.64001, 11.95693 (Exempel KTC:s kontor på Datavägen). Detta ska fyllas i på fliken "Geography". Observera att decimaltecknet ska vara komma om din dator är inställd som svensk. (Inmatningsfältet får röd inramning så länge decimaltecknet är fel.)
Konfigurera byggnadsarea
Eftersom byggnadsarea ibland varierar över tid (om- och tillbyggnader), hanterar systemet areor i en separat datakälla, Byggnads-Area.
Även här finns en kund-nod, automatiskt skapad då kunden skapades.
Under denna skapar systemet en byggnadsreferens för varje byggnad.
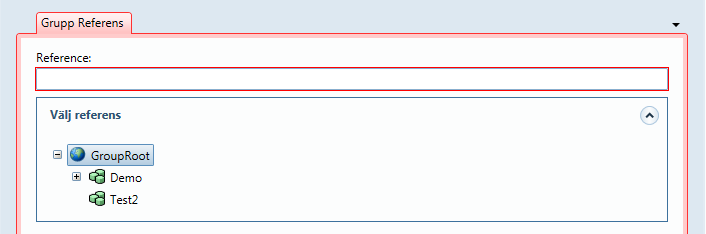
Under byggnadsreferensen skapar man en Area-referens. I den ska man välja in en av de areatyper som finns definierade. Saknas den man önskar, så kan man här också skapa en ny.
Normalt används typerna, BOA (bostad), LOA (lokal) och ATemp (uppvärmd area).
Under Area-referens, skapa ett "Byggnads Area värde". Detta består av startdatum, eventuellt slutdatum, och area i m2<\sub>.
Knyta mätare till byggnad
Då både mätare och byggnad finns, koppla mätare till rätt byggnad genom att med musen dra mätaren från "Topologi" över till "Grupper", och där släppa mätaren på rätt byggnad.
Alternativ: Markera byggnaden i grupper, och lägg till "Node reference". Välj där in din mätare.
Sätt upp beräkningar
Systemet kan självt generera en standarduppsättning av beräkningsjobb:
-
Öppna datakällan Analyser->Kunder.
-
Högerklicka på den nya kunden, och välj "Generate Analyser Calculation Jobs".
-
Alternativt välj "Attach to existing jobs" för att lägga till jobben i en redan skapad jobbsekvens.
Systemet kommer då att, i datakällan Entiteter->Jobb, under noden "Analyser Calculation Jobs", skapa en jobbsekvens med de beräkningar som behövs för att energiuppföljningen ska fungera.
Nu är det fritt att justera jobben efter eget gottfinnande, och anpassa dem för att få bästa funktion för aktuell kund.
Beräkna areor
När en mätare kopplas till en byggnad så beräknas area som mätaren betjänar. Den informationen sparas på mätaren. Om fler mätare med samma produktionstyp och/eller nytta kopplas till samma byggnad så delas arean från byggnaden på antalet mätare.
För att byggnaders och fastigheters betjänade areor skall uppdateras så måste ett beräkningsjobb köras.
När alla mätare är kopplade:
- Kör served area summary calculator jobbet för att skapa betjänings areor på alla byggnader och fastigheter.
Jobbet kan köras på hela servern eller på en specifik kund genom att i jobbet filter välja en kunds summerings nod i topologin.
Konfigurera kostnader
För att kunna beräkna kostnader för mätare så måste vi definiera prismodellen. För detta behövs följande:
-
Kostnadstyper. T.ex:
-
Löpande avgifter
-
Fasta avgifter
-
Miljöbelastning
-
-
Tariffer. T.ex:.
-
Pris per enhet/period
-
Formel för staffling
-
Avancerad formel som tar hänsyn till andra data i form av importerade parametrar.
-
-
Kopplingar mellan mätare och tariffer.
- Varje mätare kopplas till en eller flera tariffer vid olika tidsperioder.
Kostnadstyper blir tillgängliga för alla kunder. Tariffer går att skapa som gemensamma eller som kundspecifika.
Kostnadstyper
Kostnadstyper skapas i datakällan Analyser > Cost types. Om kostnader skall importeras så måste det finnas en matchande kostnadstyp för alla importrader.
-
Välj att skapa en ny nod.
-
Välj nodtypen Cost type node.
-
I fönstret som dyker upp fyll i följande:
-
Name: Visningsnamn för sorten. T.ex. Fjärrvärme energikostnad.
-
Description: Beskrivning om förtydligande behövs.
-
Class: välj mellan typerna Fast kostnad/rörlig kostnad/Miljöbelastning
-
Production type: Välj vilken produktionstyp kostnaden skall gälla för. T.ex. FV för fjärrvärme.
-
Exclude from total cost: kryssa i rutan om kostnader av typen inte skall tas med i totalsummor. (används endast i special fall)
-
Tariffer
Tariffer skapas i datakällan Analyser > Tariffs.
-
Välj att skapa en ny nod.
-
Välj nodtypen Tariff node.
-
I fönstret som dyker upp fyll i följande:
-
Name: Visningsnamn för tariffen. T.ex. Fjärrvärme energikostnad.
-
Description: Beskrivning om förtydligande behövs.
-
Supplier: Välj leverantör från listan. Nya leverantörer kan skapas i datakällan Analyser > Supplier.
-
Cost type: Välj kostnadstyp som tariffen skall gälla för.
-
Running cost, Kr per: Välj vilken enhet som skall gälla för tariffen.
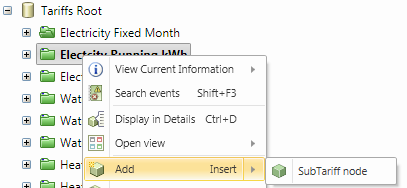
-
Efter att tariffnoden är skapad måste vi konfigurera kostnaden och för vilken period tariffen skall gälla. Detta gör vi genom att lägga till en "Sub Tariff node" på den Tariff nod som vi skapat.
-
I fönstret som dyker upp fyll i följande:
-
Valid from: Fyll i datum från den datum du vill att tariffen skall gälla för.
-
Valid to: Fylls normalt inte i då inställningarna är gällande tills en ny "Sub Tariff node" med nya villkor skapas.
-
Cost per "Unit": Skriv in värdet för kostnad. Enheten kan vara i mängd eller period, t.ex. MWh eller månader. Detta hämtas från tariffens kostnadstyp.
-
Script: Skriv in det skript som skall gälla för kostnad.
-
Använd endast "script" eller "cost per unit". Fylls båda i så används "cost per unit".
Tariff Group node
I vissa fall kan det vara smidigt att skapa en grupp som består av flera tariffer. På detta sätt kan man effektivisera produktionen avsevärt när man kopplar mätare till en grupp av tariffer istället för till varje tariff.
-
Välj att skapa en ny nod.
-
Välj nodtypen Tariff Group Node.
-
I fönstret som dyker upp fyll i följande:
-
ID: Visningsnamn för tariffgruppen. T.ex. Grupp energikostnader.
-
Tariffs: Lägg till de tariffer som skall ingå i gruppen.
-
Mätartariff
Kopplingar mellan mätare och tariffer som skall gälla för mätaren görs i datakällan Analyser > Meter Tariffs.
-
För varje tariff som skapats i datakällan tariffer så finns det en Tariff Node reference som vi kan koppla mätare till.
-
Markera en Tariff Node reference.
-
Välj att skapa en ny nod under referensen.
-
Välj nodtypen MetersTariffs node.
-
I fönstret som dyker upp fyll i följande:
-
Start date: Datum som kopplingen skall börja gälla.
-
End date: Datum som kopplingen upphör att gälla. Om datum ej anges så gäller kopplingen tills vidare.
-
Groups included to tariff: Välj önskade mätare genom att applicera tariffen på en grupp. Mätare i gruppen filtreras så att bara de av med samma kostnadstyp som tariffen inkluderas.
-
Nodes included to tariff: Välj önskade mätare genom att välja individuella mätare i strukturen. Alternativt väl ett mätar-pack.
-
-
Klicka på OK för att bekräfta och skapa kopplingen.
Importera data
För att föda beräkningarna kan värden importeras nu. Lär mer om importer under kapitel 4.2.
Systemet förväntar sig komplett data utan fel. Vi kan beräkna från timmdata eller dygnsdata eller månadsdata. Om systemet får timmar så måst det få alla 24 timmar per dygn för att göra sina beräkningar. Samma gäller för dagar i en månad. Kostnader beräknas endast på månadsupplösning.
Kör kundens beräkningssekvens
När förbrukningar är importerade:
- Kör kundens jobbsekvens för att summera, beräkna och fördela förbrukningar och kostnader.
Hur du skapar och konfigurerar en sekvens beskrivs i kapitel Sätt upp beräkningar.
Exempelkonfiguration
FieldSinks
Fältsänkor är systemets kopplingar till databaser. Vi måste skapa fältsänkor för att lagra data som vi importerar, beräknar och presenterar. Namngivningen av fältsänkorna och databaserna är helt fri och kopplat till funktion i modulen Analyser Settings som beskrivs i kapitel 6.2. FieldSinks hittar du under Datakälla > Entities > Data Field Sinks.
Timvärden
Standardnamnet är ProcessedData_Hour.
Dagsvärden
Standardnamnet är ProcessedData_Day.
Månadsvärden
Standardnamnet är ProcessedData_Month.
Alarms
Standardnamnet är Alarms.
Klimatdata
Standardnamnet är ClimateData.
Parametrar
Standardnamnet är ParameterData.
Energisignatur
Standardnamnet är PowerSignature.
Analyser Settings
Denna modul används för att koppla olika fältsänkor till de interna funktionerna. Analyser Settings(Inställningar) hittar du under Datakälla > Analyser > Inställningar.
Field Processors
Fält processorer används för att utföra olika beräkningar. Dessa processorer har olika inställningsmöjligheter beroende på vilken typ av beräkning de är tänkta att användas för. Fält processorer hittar du under Datakälla > Entiteter > Dataprocessorer.
Klimatkompensering
För denna beräkning används en processor av typen Analyser ClimateCorrected Consumption Calculator.
Förbrukning Timmar -> Dygn -> Månad
För dessa beräkningar används en processor av typen Analyser Consumption Aggregation FieldProcessor.
Förbrukning Timmar, Dygn och Månadssummering
För dessa beräkningar används en processor av typen Analyser Consumption Summary Calculator.
Kostnadsberäkningar
För denna beräkning används en processor av typen Analyser Cost Calculator.
Summering av kostnader
För denna beräkning används en processor av typen Analyser Cost Summary Calculator.
Prognostisering av förbrukning
För denna beräkning används en processor av typen Analyser Prognosis Calculator.
Beräkning av betjänad area
För denna beräkning används en processor av typen Analyser Served Area Summary Calculator.
Beräkning av area
För denna beräkning används en processor av typen Analyser Meter Area Calculator.
Förbrukningsfördelning Timmar, Dygn och Månad
För dessa beräkningar används en processor av typen Analyser Consumption Sub Meter Calculator.
Kostnadsberäkning(Total)
För denna beräkning används en processor av typen Analyser Total Cost Calculator.
Kostnadsberäkning(Total inkl. moms)
För denna beräkning används en processor av typen Analyser Total Cost VAT Calculator.
Beräkning av effektsignatur
För denna beräkning används en processor av typen Analyser Power Signature Calculator.
Beräkning av förbrukningslarm
För denna beräkning används en processor av typen Analyser Consumption Alarm FieldProcessor.
Definiera parametrar
Parametrar kan importeras för att sedan användas i exempelvis tariffberäkningar.
Parametrar skapas under Datakälla > Analyser > Parametrar.
De inställningar som kan göras är:
Namn: Namn på den specifika parametern. Det är detta namn som man hänvisar till i exempelvis tariff skript. Ett tariff skript kan se ut så här:
(RT_TEMP-JMF_RT_TEMP) * 5
I exemplet är RT_TEMP och JMF_RT_TEMP namn på parametrar.
Typ av data: här anges vilken typ av data parametern är. Välj: String, Numeric, Boolena, DateTime eller TimeSpan.
Typ av aggregering: Här väljs vilken typ av aggregering som skall tillämpas. Välj: Ingen, Summering, medel eller viktat medelvärde.
Speciella mätarkonfigurationer
Lastpunkter
Lastpunkter kan användas då data från en mätare behöver synas på annat ställe i grupp-trädet, antingen som en kopia, eller som en beräkning mellan mätare (summa, skillnad...). Ibland kan t ex två olika kunder kunna hantera samma mätare.
Under lämplig sorteringsnod (rätt kund och produktionstyp), Lägg till->Linear Loadpoint. Ge ett ID som är unikt i hela systemet, och om så önskas ett Namn (detta visas i så fall för användare).
Under fliken Analyser, gör samma inställningar som för vanliga mätare.
Under fliken Nodes välj "Only history information available." Välj sedan in önskade mätare.
Skapa jobb
För att data ska hamna på lastpunkten behöver man skapa ett utläsningsjobb:
-
Gå till datakälla Entiteter->Jobb.
-
Tidigt i jobb-sekvensen för aktuell kund, lägg till ett "Readout job", ge lämpligt ID.
-
Under fliken "Content", sätt Readout Types till Historical.
-
Klicka bort "Include children"
-
I "Read historical data from field sink", lägg till fältsänka där refererade mätare har sin data, t ex ProcessedDataHour.
-
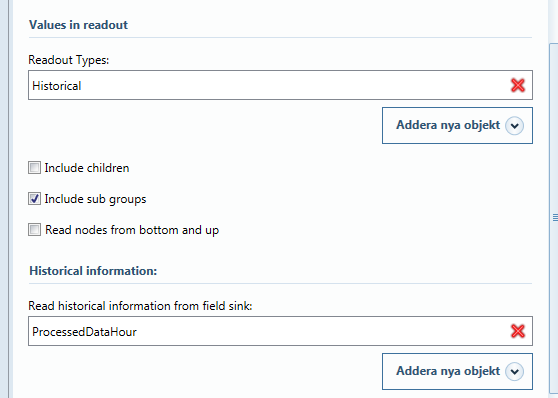
Under fliken Nodes, lägg till alla lastpunkter i "Nodes selected for this job". Om man har många lastpunkter går det också bra att skapa en grupp, och sedan välja in den under fliken "Groups".
-
Under fliken Sinks, välj vara data ska hamna. Normalt samma fältsänka som har lästs, alltså oftast ProcessedDataHour.
Kör jobbet en gång.
Filtrera utdata(fält) från lastpunkten
Nu när en avläsning har gjorts kan man välja vilka fält man fortsättningsvis ska hantera i lastpunkten. Exempel:
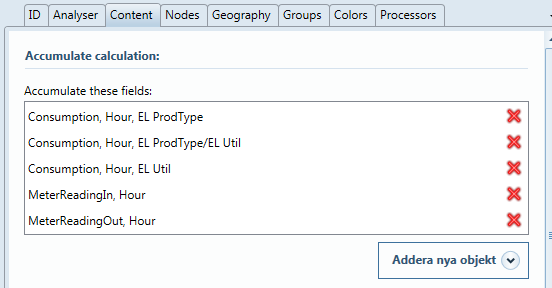
I det här fallet har vi fått med mätarställningar in och ut. De kanske inte är nödvändiga att ha med i fortsättningen. Klicka i så fall bort dem med det röda krysset. Förbrukningar enligt produktionstyp och nytta är precis vad vi önskar ha, så det ser ut att ha blivit rätt.
När ett jobb begär data från lastpunkten så är det de fälten som är valda här som skickas vidare till beräkningarna.
Normalårskorrigering och prognos/estimering
Normalårskorrigering görs för att man skall kunna jämföra förbrukningar mellan olika år. Energiportalen använder sig av SMHI:s värden för graddagar/energiindex.
Prognos och estimering används för att fylla i data som saknas. Antingen inte kommit in eller som ligger i framtiden.
Dessa beräkningar görs på månadsdata, och beskrivs i referensdokumentet.
Inställningar
- Om klimatkompensering ska göras eller inte: ställs in på nytta, men kan också ställas in på mätare.
- Användning av graddagar eller energiindex: ställs in på byggnad.
- Typ av prognosberäkning (föregående år eller normalår): ställs in på mätare.
- Antal månader för normalårsprognos: ställs in på kund.
- Månader undantagna från normalårsprognos: ställs också in på kund.